Reasoning from sequences of raw sensory data is a ubiquitous problem across fields ranging from medical devices to robotics.
These problems often involve using long sequences of raw sensor data (e.g. magnetometers, piezoresistors) to predict
sequences of desirable physical quantities (e.g. force, inertial measurements).While classical approaches are powerful for locally-linear prediction problems,
they often fall short when using real-world sensors.
These sensors are typically non-linear, are affected by extraneous variables (e.g. vibration), and exhibit data-dependent drift.
For many problems, the prediction task is exacerbated by small labeled datasets since obtaining ground-truth labels requires expensive equipment.
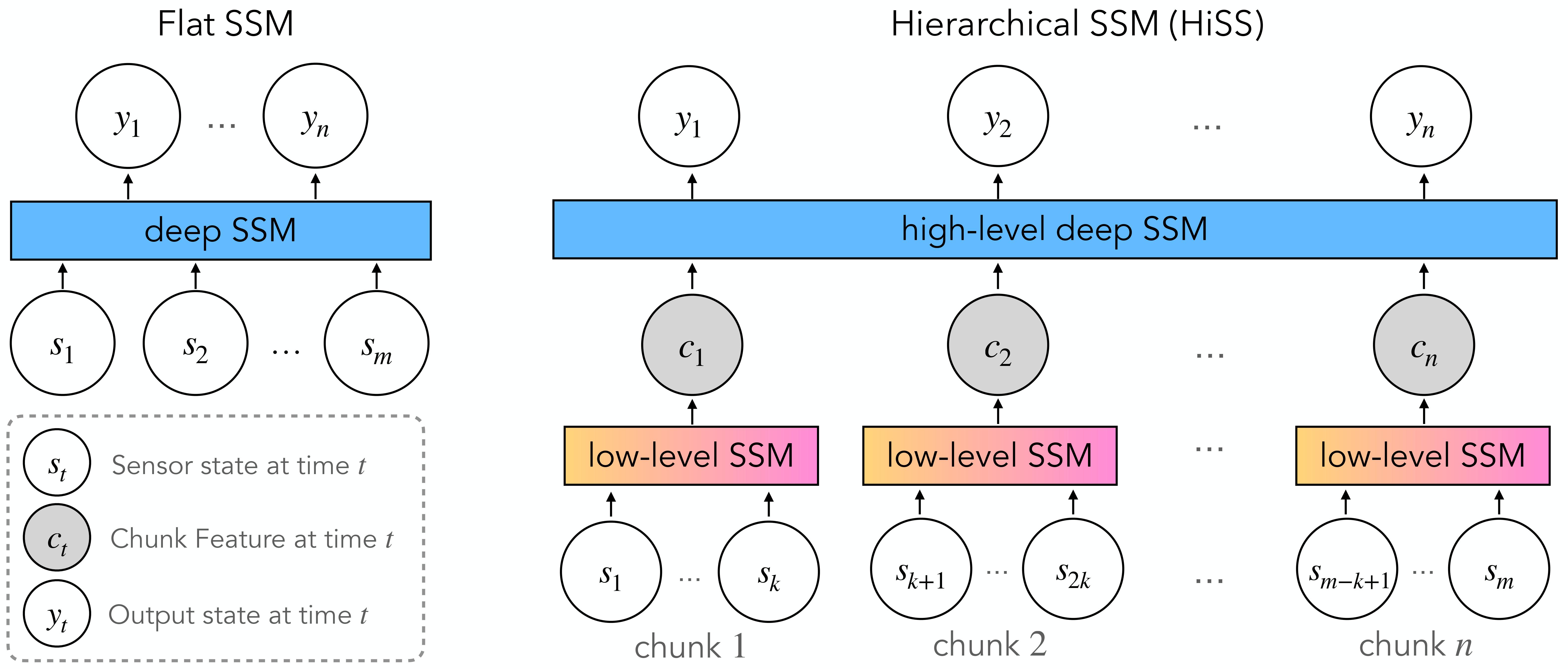
In this work, we present Hierarchical State-Space Models (HiSS), a conceptually simple, new technique for continuous sequential prediction.
HiSS stacks structured state-space models on top of each other to create a temporal hierarchy.
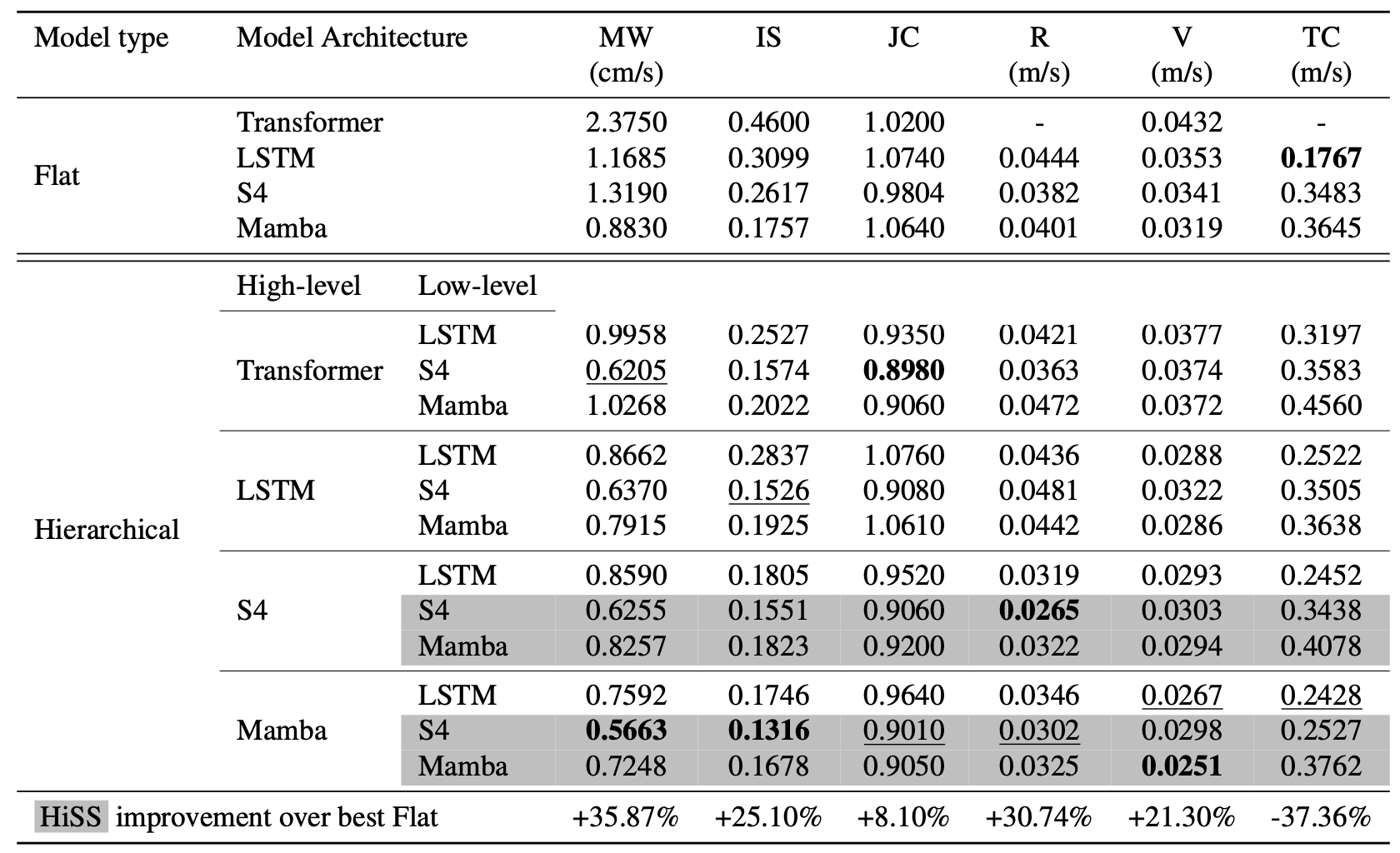
Across six real-world sensor datasets, from tactile-based state prediction to accelerometer-based inertial measurement,
HiSS outperforms prior sequence models such as causal transformers, LSTMs, S4, and Mamba by at least 23% on MSE.
Our experiments further indicate that HiSS demonstrates efficient scaling to smaller datasets and is compatible with
existing data-filtering techniques.